- 분류 전체보기 (681)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- es6
- JavaScript
- Kotlin
- 공정능력
- tomcat
- GIT
- plugin
- SSL
- Sqoop
- mapreduce
- NPM
- xPlatform
- Eclipse
- MSSQL
- vaadin
- hadoop
- SPC
- Spring
- 보조정렬
- react
- mybatis
- Express
- table
- Android
- IntelliJ
- window
- SQL
- Java
- Python
- R
- Today
- Total
목록전체 글 (681)
DBILITY
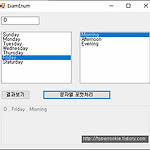 c# Enumeration foreach
c# Enumeration foreach
기록해 두자. 어차피 기억하지 못할테니까..ㅎㅎ 리스트박스에 아이템을 추가하는 예제다. using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Windows.Forms; namespace ex001 { public partial class ExamEnum : Form { public ExamEnum() { InitializeComponent(); } string strName = ":D"; private en..
http://www.iconarchive.com/
https://github.com/Microsoft/VisualStudioUninstaller/releases
#define IsControlKey() (0x8000 == (0x8000 & GetKeyState(VK_CONTROL))) #define IsShiftKey() (0x8000 == (0x8000 & GetKeyState(VK_SHIFT)))
API를 통해 직접 작성해 보았다. 다시드는 생각이지만, MessageBox의 MB_OK가 정말 싫다. #include LRESULT CALLBACK WndProc(HWND hWnd, UINT uMsg, WPARAM wParam, LPARAM lParam) { if (uMsg == WM_DESTROY) { PostQuitMessage(0); } else if (uMsg == WM_LBUTTONDOWN) { MessageBox(hWnd, "Mouse Left Button Click", "Information", MB_OK); } return DefWindowProc(hWnd, uMsg, wParam, lParam); } int WINAPI WinMain(HINSTANCE hInstance, HINSTANC..